Many are the times when you need to extract data from a PDF and export it in a different format to avoid the need to retype all the content for reuse. While most of us have become accustomed to fully-fledged PDF converter software, it is also possible to achieve the exact task at hand using a popular programming language like Python. Unfortunately, Python has not seen a boatload of packages that can accomplish this reliably but at the same time, there are a few that are still able to kick the ball out of the park for you.
As usual, we have gone the extra mile to let you in on the tools you can use and at the same time guide you on how to get started with them. Here, we will look at two Python tools that will come in handy to convert PDF to Excel offline. The good thing is that these tools are free to obtain and the code used can be found on Github. You will be able to transform PDF to Excel without the need to set up any software on your computer. Let’s now learn how to extract data from PD files.
Method 1). Using PyPDF2 and PDFTables
PDFTables provides you with an API that you can use in combination with Python to convert PDF to Excel. Actually, it will help you convert any PDF file to either Excel, CSV. XML or HTML depending on which one works best for you. For the sake of this article, we are going to put our focus in the PDF to CSV or Excel conversion process. This will happen by just running a very simplified Python script that will eventually save you a great deal of time and effort. In order to help you make the most out of this tool, below is a comprehensive guide that will sail you to the end of a successful task to convert PDF to Excel using Python. Let’s get started.
- 1. From the Anaconda website, install Anaconda. This will install Python on your computer and at the same time have pip set up to help install packages.
- 2. Set up the PDFTables Python library. In the directory containing the PDF file to be converted, start a command interface, input the code below, and hit “Enter”.
pip install git+https://github.com/pdftables/python-pdftables-api.git
If you get a git related error, install it from here.
- 3. Create a Python script containing the code below. This is the code that will be necessary to make the conversion successful.
import pdftables_api
c = pdftables_api.Client(‘my-api-key’)
c.xlsx(‘input.pdf’, ‘output’)
#replace c.xlsx with c.csv to convert to CSV
#replace c.xlsx with c.xml to convert to XML
#replace c.xlsx with c.html to convert to HTML
A few things to do here though include;
- Grab your API key from the PDFTables website and replace my-api-key
- With the target PDF filename at hand, replace the pdf appropriately
- Replace output with your preferred name for the converted file.
Once you have done that, save the PyPDF2 script as convert-pdf.py in the same folder as the source PDF file.
- 4. Open a command line in the source folder and run the saved script. Click on the Address bar, type the word cmd, and hit “Enter”. Next, type in this code py convert-pdf.py and hit “Enter”.
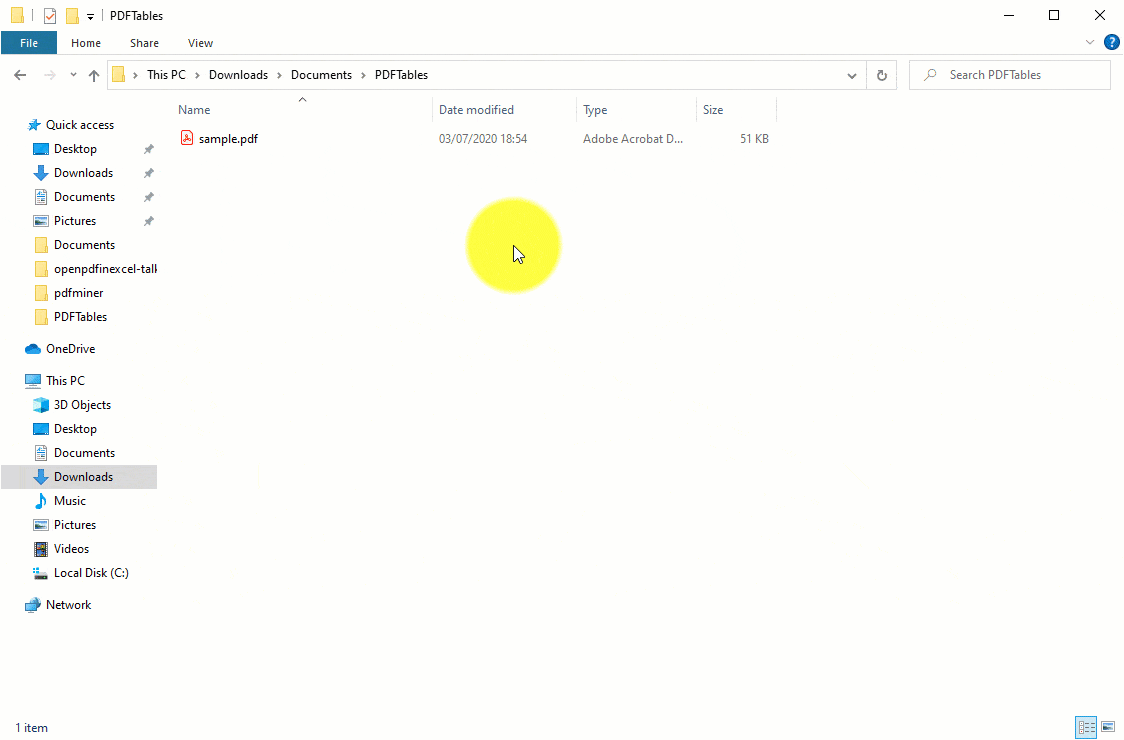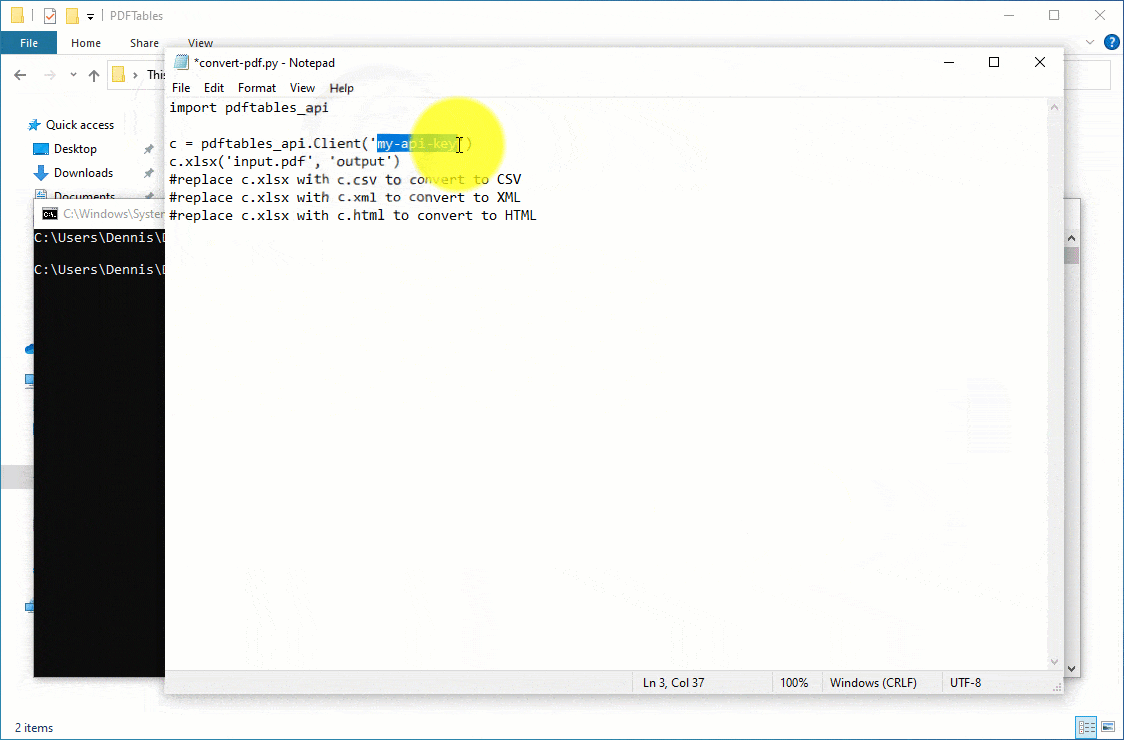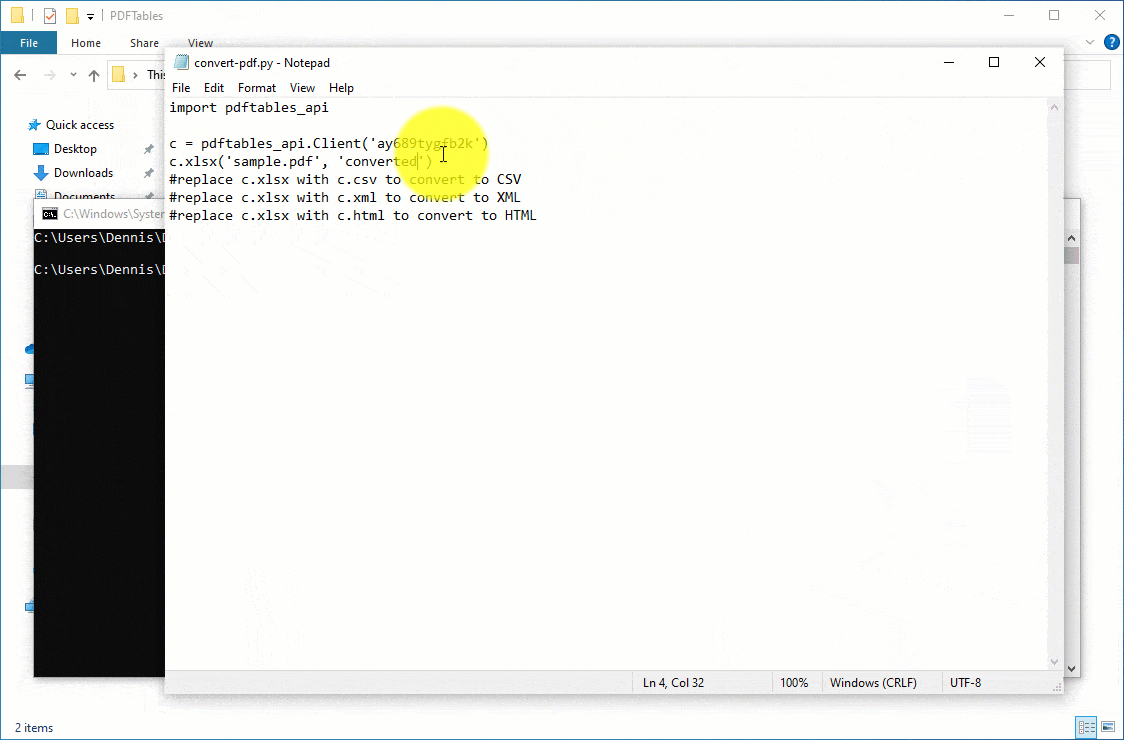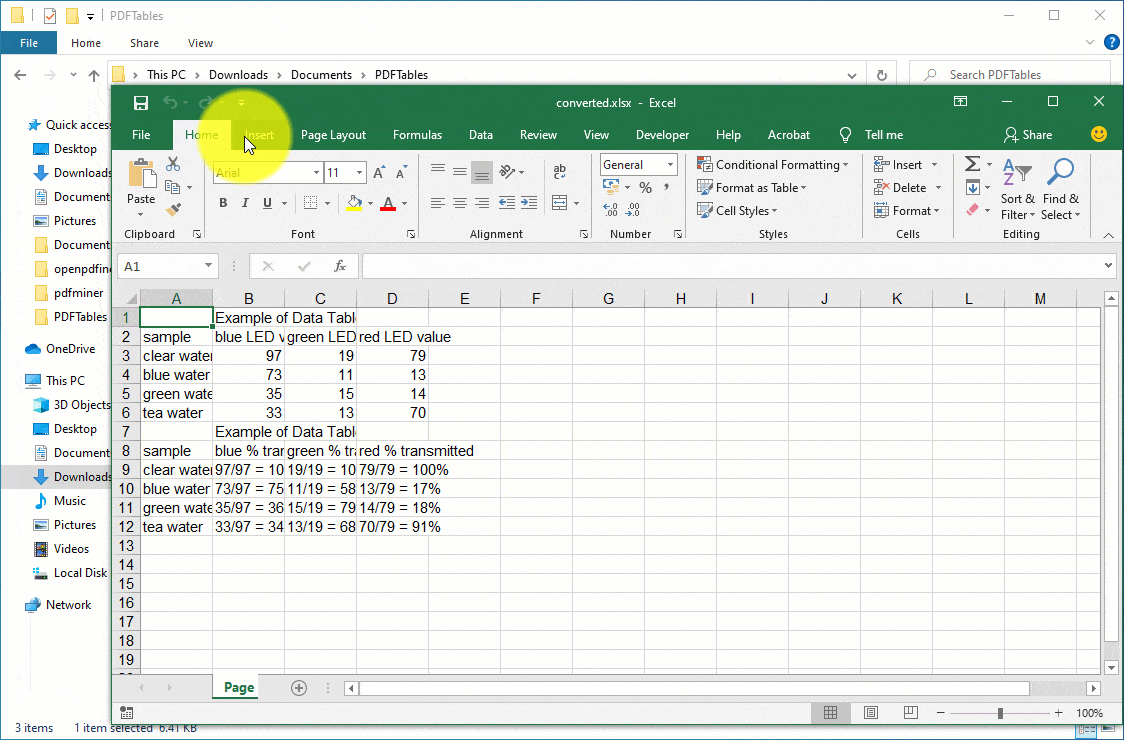
The PDF to Excel process will begin and within moments, you should be able to notice a new file with the XLSX file format in addition to the original PDF file. This will be tacit proof that you have successfully managed to convert PDF to Excel using Python.
Method 2): Using PDFMiner for Extracting Data from PDFs
PDFMiner has been crafted as a suitable tool when you need to parse and extract data from PDF files. It works on a Python base and that means you need to have Python set up on your computer before getting started. Its main focus lies in the extraction and analysis of textual data and is able to give the location of text with accompanying font and line information.
You are also able to convert encrypted PDF to CSV though you have to input the right password for the file. Better yet, this tool is open source and is available for free from Github. As much as possible, this tool to extract data from PDF to Excel using Python ensures that the original layout of the text is maintained. Here are the steps to use PDFMiner.
- Create a Folder and place the target PDF file inside. This is largely for convenience purposes though this tool can be run from any folder once installed.
- Install Python 3.6 or newer on your computer. This is necessary since PDFMiner is a Python tool.
- Open a command-line interface in the PDF directory. From the File Explorer “Address bar”, type in the word cmd and hit the “Enter” key.
- Install PDFMiner. Basically, type in the command “pip install pdfminer” and hit the “Enter” key on your keyboard. Wait for the process to complete.
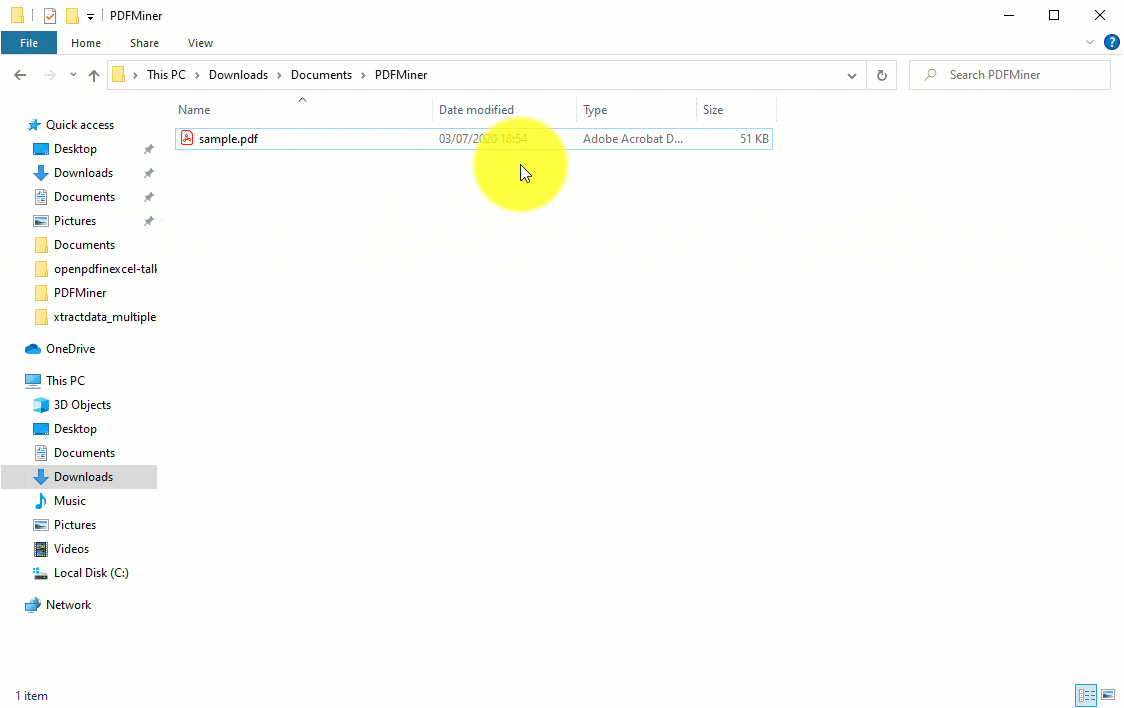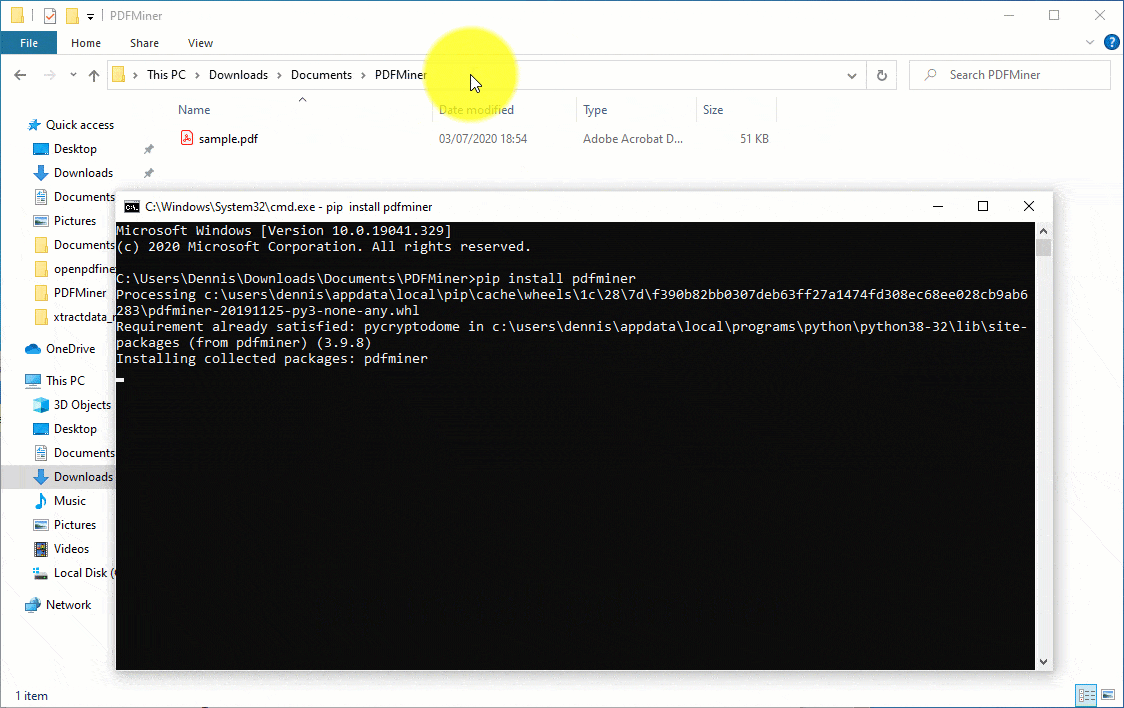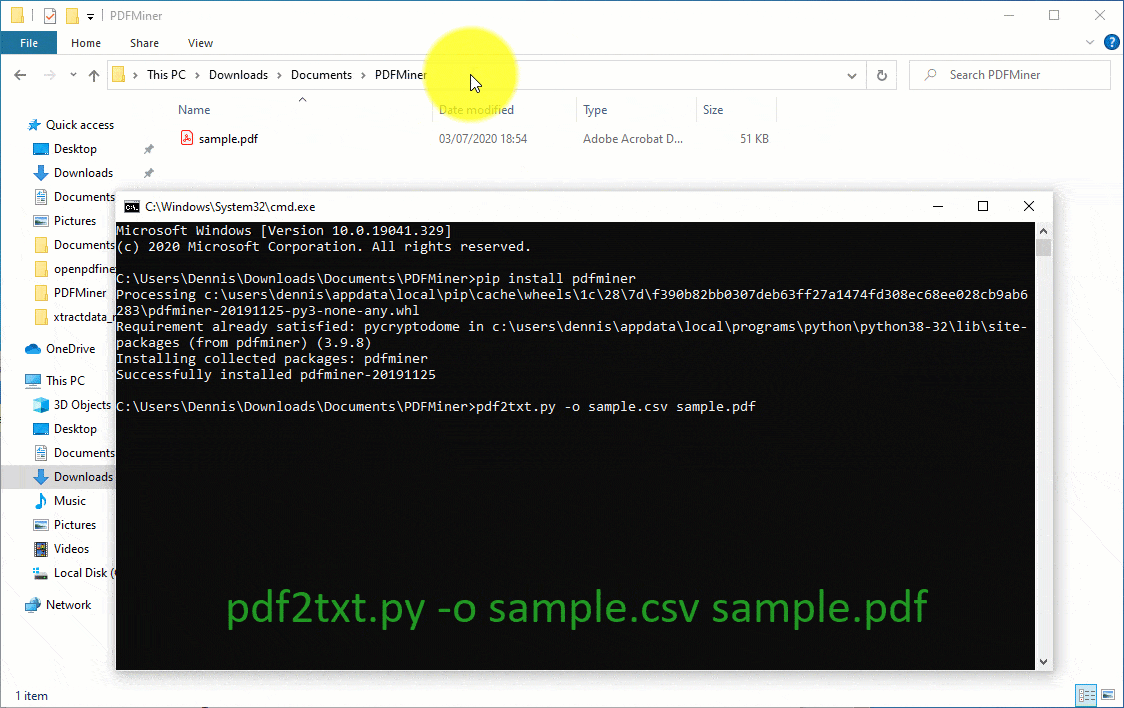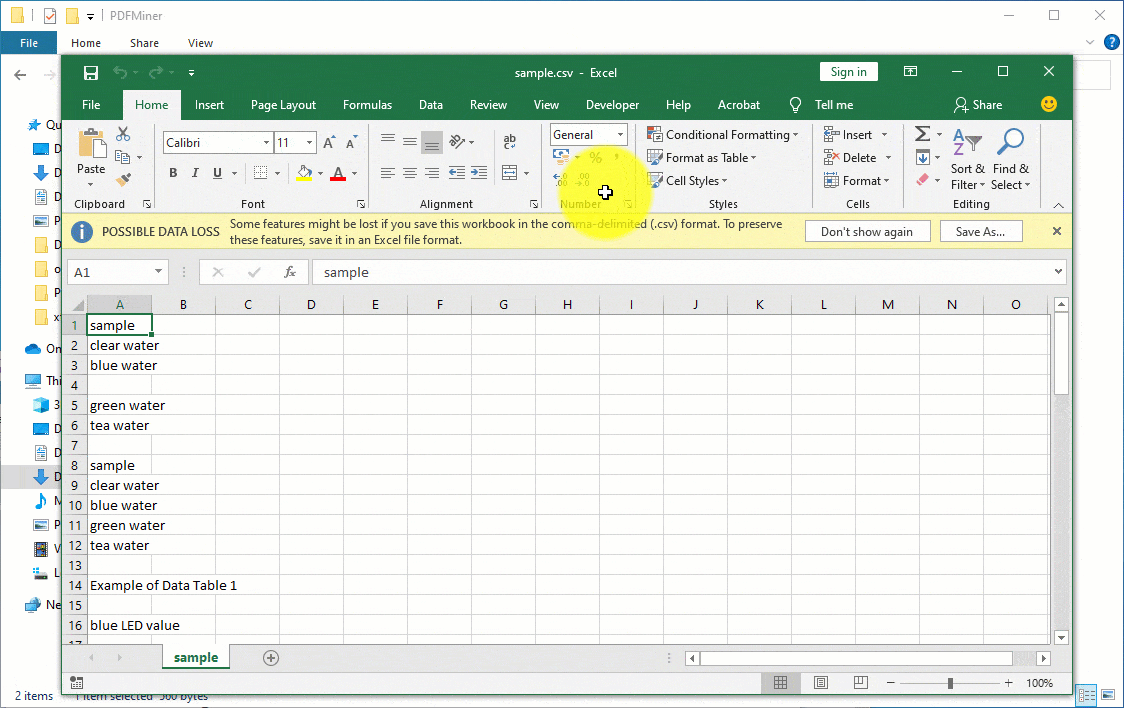
- Extract data from PDF. To do this, type the command “pdf2txt.py -o sample.csv sample.pdf” and hit the “Enter” key. Remember to replace the word “sample” with your PDF filename. To break down the command, we are simply extracting data from the sample.pdf and outputting the data in the file sample.csv. Opening the output file will reveal the extracted data.
After going through the steps above, you should be having a file containing your extracted data ready for opening. Keep in mind that you have to input the right source PDF filename and the output filename that you prefer. You can also output to XLSX or XLS format if you don’t want to use the CSV format.